

Table of Links
-
Experiments
4. Differentiable Structural Information
In this section, we first establish a new formulation of structural information (Li & Pan, 2016), and then give a continuous relaxation to the differentiable realm, yielding a new objective and an optimization approach for graph clustering without the predefined cluster number. We start with the classic formulation as follows.
Definition 4.1 (H-dimensional Structural Entropy (Li & Pan, 2016)). Given a weighted graph G = (V, E) with weight function w and a partitioning tree T of G with height H, the structural information of G with respect to each non-root node α of T is defined as
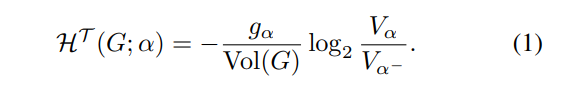
In the partitioning tree T with root node λ, each tree node α is associated with a subset of V, denoted as module Tα, and the immediate predecessor of it is written as α −. The module of the leaf node is a singleton of the graph node. The scalar gα is the total weights of graph edges with exactly one endpoint in module Tα. Then, the H-dimensional structural information of G by T is given as,
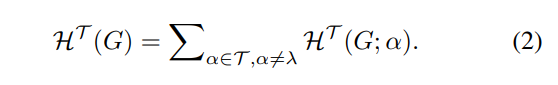
Traversing all possible partitioning trees of G with height H, H-dimensional structural entropy of G is defined as
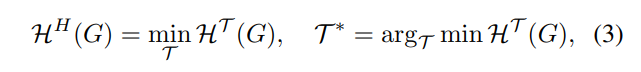
where T ∗ is the optimal tree of G which encodes the self-organization and minimizes the uncertainty of the graph.
The structural information in Eq. (2) is formulated node-wisely, and cannot be optimized via gradient-based methods.
Authors:
(1) Li Sun, North China Electric Power University, Beijing 102206, China ([email protected]);
(2) Zhenhao Huang, North China Electric Power University, Beijing 102206, China;
(3) Hao Peng, Beihang University, Beijing 100191, China;
(4) Yujie Wang, North China Electric Power University, Beijing 102206, China;
(5) Chunyang Liu, Didi Chuxing, Beijing, China;
(6) Philip S. Yu, University of Illinois at Chicago, IL, USA.
This paper is